Asynchronous garbage collection with CRDTs
So CRDTs are very very nice data structures awesome for eventual consistent applications like riak, or the components of Project-FiFo. So they have one big drawback, most of them collect garbage, and over time that can sum up to a lot making them pretty unpractical in many cases. Collecting this garbage is a bit tricky, since usually it means synchronising the data - which going back to the eventual consistent stuff prevents either A or P.
I want to outline some thoughts here how one could deal with this issue. As usual the idea here isn't without tradeoffs, it does impose certain constrains on the systems behaviour and does not fit every behaviour in exchange of allowing garbage to be disposed of without the need of synchronisation. Now then, lets dive right in.
What's that trash?
We start with understanding what the garbage is that sums up. To allow CRDTs to work the way we do, they need to store some kind of history or legend of how the current state (version/value) of the CRDT came to existence.
If we look at a OR Set for example the history of this set is stored by recording all elements ever added along with all elements ever deleted - elements are tagged to be unique too so adding 5, removing 5 and adding 5 again and removing that again, leaves not a data structure with 0 elements but one with 4. That said there are ways to optimise the OR Set bot lets ignore this for the sake of the example. We can't just store an empty list since we need to make sure that when another copy of the same set can recreate the steps even if it just missed one of the events.
Actually we could, if we would synchronise all copies, say hey ¯from now on you all agree that the new baseline (this is bold since it will come up a few more times) is an empty set from now on. And doing that we would have garbage collected the OR Set, disposed of data that isn't directly relevant to the current state any more.
If we don't guarantee that all objects are garbage collected to the same state, we face a real issue, since the new baseline will cause quite some trouble since the partially applied effects will just be applied again and possibly cause them to be doubly applied. Or in short, partially applied GCing will cause the CRDT to stop functioning.
Things get old.
Looking at the data that gathers and how it is distributed there is one observation to be made: the older a change in state is the more likely it is to be present in all replicas. It makes sense, with eventual consistency we say ‘eventually’ our data will be the same everywhere, and the chances of ‘eventual’ are growing the older the change is since it will get more chance to replicate. (mechanisms similar to riak's AAE greatly help here).

So generally there is a T100 from which point on older data is shared between all instances and by that no longer relevant if we could just garbage collect it. But we don't want synchronous operations, nor do we want partial garbage collection (since that rally would suck).
Back to state, we know which ones we want to garbage collect, lets say we record not only the state change but a timestamp, a simple non monotonic system timestamp, it's cheap to get. Keep in mind T100 is well in the past, so if the precision of the times taps is good enough to guarantee that a event at T0 can not travel back behind T100, it's OK if order between T0 and T99 changes all the time, we don't really care about that so lets store the state data in a way that helps us with this:
T0 [S0,S1, …, Sn] T100 [Sn+1, …, Sn+m]
A trash bin
But since it would really suck (I know I'm repeating myself) if we partially GC the data we want to be sure that we agree, so would could go and ask all the replicas for their old data (older then T100). Yet this approach has a problem, for once T100 will shift in the time we check, then this might be more data to move then we care for.
So lets use a trash bin, or multiple once order our data in them so you've some groups of old messages, bunched together which can be agreed on, no matter on the time moving and they are smaller portions. Something like this
… T100 [Sn+1, …, Sn+100] [Sn+101, …, Sn+200]…
So we just have to agree on some bucket to garbage collect, since so if there is another half full bucket now since T100 has moved since the agreement we don't really care about that. Thanks to the fact that operations are commutative we also can garbage collect in a non direct order, so it's not a biggie if we take just one bucket and not the oldest one.
We're still left with transmitting (in this example) 100 elements to delete and haven't solve the problem of partial garbage collection, but at least we're a good step closer, we've put the garbage in bins now that are much easier to handle then just on a huge pile.
A garbage compactor
Lets tackle the last two issues we do a little trick, instead of sending out the entire bucket we compress it, create a hash of it and send this back and forth, so instead of:
[Sn+1, …, Sn+100]
We tag this bucket with a hash (over it's content) and the newest timestamp of the first element. Since it's older then T100 we do not need to worry of it changing and recreating the hash, and we get something like this:
(hash, TSn+1)[Sn+1, …, Sn+100]
To agree on buckets to collect and to give the collect order we just need to send the hash and timestamp and an identifier, this is pretty little data to send forth and back. This solves the send much data problem, curiously it also helps a lot with the partial garbage collection status.
A schedule for garbage collection
With only the buckets tag identifying it we can solve the partial collection issue, we just treat garbage collection as just another event, storing it and replaying it if it wasn't present in a old replica. So we gradually progress the baseline of a replica towards the common baseline somewhat like this:
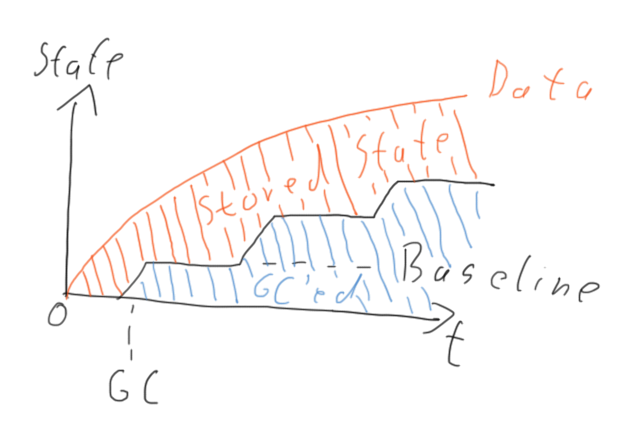
Ideally we store the GC operations in a own list and since we can easier apply it then and guarantee that the GC events are synchronised and applied before other events.
That's it, and should be a somewhat working implementation of asynchronous garbage collection for CRTDs. But it's not perfect so lets take a look at the downsides before we end this.
Lets be honest, it still has a downside
This concept of GCing does not come for free, the data structure required isn't entirely trivial so it will add overhead, even so the current implementation is pretty cheap when adding the events in right order, wrong order will cause additional overhead because it might cause elements to shift around in the structure.
It requires events to be timestamped, even so there is no requirement for absolute order, this adds a constraint to messages and events that wasn't there before. Also this is additional work and space that is consumed.
We need to define a T100 for the system and guarantee it, and find a balance of choosing a big enough T100 to ensure it's correctness while keeping it small enough to not keep a huge tail of non garbage collected events. That said this can be mitigated slightly by using a dynamic T100 for example put record when a object was last written to all primary nodes.
If T100 isn't chooses correctly it might end up getting really messy! if a elements slips by T100 that wasn't there it could mean that the garbage collection is broken for quite some while or worst state gets inconsistent.
Bucket size is another matter, it needs to be chosen carefully to be big enough to not spam the system but small enough to not take ages to fill, a event passing T100 but not filling the bucket isn't doing much good.
This is just a crazy idea. I haven't tried this, implemented it or have a formal prove, it is based on common sense and my understanding on matters so it might just explode ;)